School Vouchers Bot
Introduction
The goal of this project was to integrate a school vouchers chatbot into a special report, marking our first public-facing, internally developed chatbot tool. To maintain journalistic integrity and prevent misinformation, we restricted the chatbot’s access to a curated set of vetted articles. By leveraging Retrieval-Augmented Generation (RAG) technique, the chatbot retrieves information only from pre-selected, published content, ensuring responses are fact-based and up to date while maintaining the integrity of our reporting and upholding the highest editorial standards.
Building the Chatbot
As of March 2024, a survey paper on RAG identifies three common approaches to building a Retrieval-Augmented Generation (RAG) application: Naive RAG, Advanced RAG, and Modular RAG. In the Naive RAG approach, relevant articles are fed into a large language model (LLM), which then generates responses. However, this method has significant drawbacks—it may fail to retrieve the most relevant information and is prone to hallucination. To address these issues, the Advanced RAG approach provides more control over how information is stored, retrieved, and processed. The Modular RAG was beyond what our project required. The Advanced RAG diagram below illustrates the data flow from storage to answer generation.
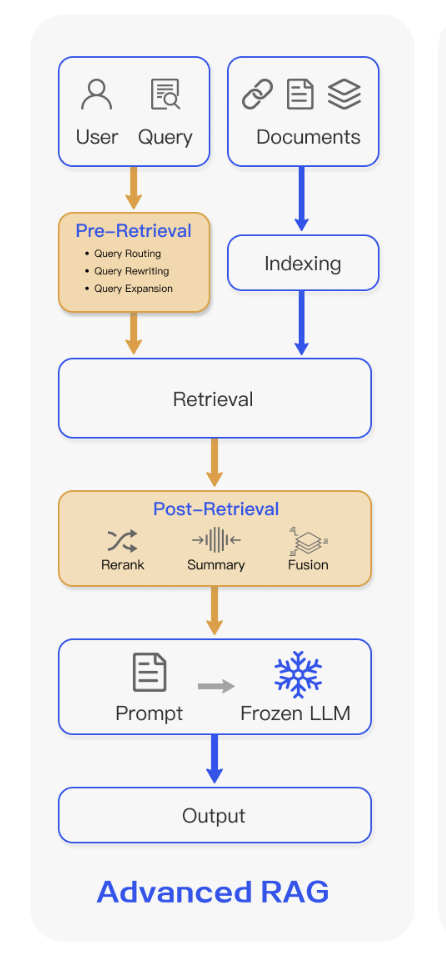
Source: Retrieval-Augmented Generation for Large Language Models: A Survey
How is it built?
To make our chatbot accurate and efficient, we structured its data pipeline around tagged articles. Whenever a relevant article is tagged or updated, it is added to the bot’s knowledge base. To prioritize fresh information, we assign a recency score to each article, ensuring newer content is ranked higher. We store this data in a Weaviate vector database. To improve search accuracy, we break articles into small chunks and add context, making it easier for the chatbot to find the most relevant details. Before retrieving answers, we filter out harmful or inappropriate questions using OpenAI’s moderation API and refine user queries for better results. We used cohere to further re-rank retrieved data to prioritize the most useful article chunk. For generation, we use GPT-4.0, fine-tuned to focus on relevant content, avoid incorrect answers, and provide clear, well-cited responses. The frontend, built with Streamlit, ensures a smooth user experience with real-time streaming, citation visualization, and a user-friendly interface.
Technical explanation (optional)
Read more ⬍
Data Engineering
We refined our data pipeline through multiple iterations, ultimately structuring it around tag-based ingestion. Whenever a relevant article is tagged, it is added to the bot’s knowledge base. Additionally, if an article is updated, the ingestion pipeline ensures the knowledge base reflects the latest version. To prioritize recent information, we assign a recency score to each article based on its publication date and related tags. Several approaches can be used for this, such as linear decay, exponential decay, and weighted decay, depending on how much importance you place on newer content. While we could calculate recency dynamically during retrieval, we opted to precompute it during ingestion. This reduces processing overhead when the chatbot is in use, ensuring faster response times.
Vector embeddings storage
After evaluating several storage solutions—including PostgresML and Postgres with pgvector—we chose Weaviate due to its widespread adoption and usability. Its hybrid search capabilities significantly streamline retrieval optimization.
Chunking
Effective retrieval is critical for chatbot accuracy. If irrelevant data is fed into the response generation stage, it leads to incorrect answers. To improve retrieval, (a) we split text into small chunks for better search results and (b) each chunk is contextualized by adding relevant metadata. Now that our data is ready, let's move on to the pre-retrieval stage.
Pre-retrieval
At this stage, we ensure that user queries are safe and well-structured:
Content Moderation
We use OpenAI’s free moderation API to filter out inappropriate or harmful queries. If flagged, the bot responds: “I'm sorry, I cannot provide that information.”
Query Transformation
We refine the query by: Fixing grammatical errors Adjusting context (e.g., reframing school voucher queries) Expanding the query to improve retrieval quality Once processed, the query is sent to Weaviate for hybrid search, which returns relevant results with search scores for each chunk.
Post retrieval
Recency Adjustment
To prioritize newer content, we fuse hybrid search scores with recency scores, ensuring fresh articles rank higher. Since Weaviate didn’t have a built-in date-based re-ranking method at the time, I implemented our own. (If you find an existing solution, email me!)
Reranking
Finally, we perform reranking to further improve retrieval quality. And yes we are still doing search, i.e., retrievals. Using Cohere Rerank, we rank them based on relevance and send a limited set of chunks for response generation. This approach prevents feeding irrelevant chunks to the LLM, which reduces costs and increases accuracy. For more on reranking, check out cohere, openai, pinecone, and weaviate.
Generation
After experimenting with different GPT models, we settled on GPT-4.0. Here’s how we optimized our prompts: Focus on relevant article chunks (especially recent ones) Prevent hallucinations (If no relevant data is found, do not generate an answer) Ensure conciseness, readability, and proper citation formatting One key improvement during the response generation phase was enabling streaming, which significantly reduced latency and improved user experience. Instead of waiting for a full response, users see answers appear in real time.
Frontend
This aspect of the project deserves its own blog post, especially given the contributions from our frontend developer. We built the frontend using Streamlit. Some key aspects involved making it visually similar to The Texas Tribune, citation visualization, streaming responses for a seamless user experience, and progress bars.
What it cannot answer?
The school voucher bot is designed exclusively to answer questions about school vouchers using a curated set of vetted articles. Thus, it cannot provide responses on topics outside this scope which are beyond its knowledge base. If a question falls outside its coverage, the chatbot will simply state as follow: This tool relies on voucher stories published by The Texas Tribune. Apologies, we couldn't answer your question at this time. We'll forward it to our editorial team for review. In the meantime, you can visit texastribune.org to explore more.
Testing and Deployment
We followed standard software development practices, maintaining both testing and production environments. For chatbot testing, we conducted thorough design, product, and editorial reviews, incorporating feedback from past iterations to enhance reliability and usability. To evaluate chatbot responses, our editors and journalists played a key role in assessing accuracy and effectiveness. We also used RAGAS to systematically evaluate the chatbot’s performance. Given the novelty of this technology and process, it was a learning experience for all involved. The chatbot was successfully deployed on the same day we launched the special report.
User Feedback and Insights
The chatbot performed well, receiving a wide range of user feedback. A common theme was that it provided detailed and helpful answers, making it particularly valuable for users seeking in-depth information. One of the most significant benefits was identifying questions the chatbot couldn’t answer, giving us insight into the unmet needs of Texans. This data will help us refine our coverage and better serve our audience. Since the chatbot was launched recently, we haven’t conducted a deep analysis yet. However, we’ve observed a clear trend—when we integrate the chatbot into newly published relevant stories, its usage increases.
Challenges and Lessons learned
Challenges
One of the biggest challenges was navigating new technology while learning and building alongside our team. Developing and launching the chatbot required various iterations and problem-solving. Another major hurdle was evaluating chatbot responses. While many open-source evaluation tools exist, they are not yet fully optimized, making the process time-consuming and resource-intensive. Effective evaluations require input from journalists and editors—who already have heavy workloads—which adds another layer of complexity. Additionally, the stochastic nature of LLMs makes it difficult to establish a perfect evaluation set, as writing styles are inherently subjective.
Lessons Learned
Lesson 1: Prioritize Recency
For news-oriented chatbots, recency is critical—so plan for it early. Check whether your vector database offers recency-based ranking as a built-in feature, and if not, consider implementing a custom solution. Additionally, factor recency awareness into prompt engineering to ensure the chatbot prioritizes the most up-to-date and relevant information.
Lesson 2: Invest in a Strong Evaluation Set
If you want to build a high-quality chatbot, start by developing a solid evaluation set. This set could integrate your organization’s writing style, content priorities, and domain-specific nuances. Finally, build your own set of data, in this case - news articles, alongside the evaluation set. A tailored evaluation set ensures that your chatbot aligns with your goals and consistently delivers reliable responses. Keep in mind that while the evaluation set may vary based on the chatbot’s purpose, its core structure should remain largely consistent.
Lesson 3: Build Your Evaluation Set Over Time
Evaluation during pre-deployment tasks is a resource intensive process. Thanks to a new approach, post-deployment evaluation (see Adaptive Testing for LLM-Based Applications). Post-deployment, real-world user queries become a valuable resource for improving and refining your chatbot. By saving these questions, you can gradually expand and enhance your evaluation set, thus your chatbot’s response. By incorporating these lessons, we can build more accurate, reliable, and scalable chatbots while continuously improving their ability to serve users effectively.
Future Improvements
Looking ahead, there are several enhancements we could make to improve the chatbot’s functionality and user experience
- Conversation Memory: Enable the bot to remember session-based interactions.
- Voice Features: Voice features are relatively inexpensive to integrate, yet they could significantly enhance accessibility and engagement.
- Expand Access: Extending the chatbot’s availability to SMS or other channels would make it even more accessible.
Conclusion
Building a chatbot is one of the most user-facing applications of LLMs, but a lot of it is about search and evaluation! A successful chatbot requires collaboration across teams—journalists, designers, editors, and engineers—each playing a crucial role in shaping its effectiveness. Beyond improving accessibility and engagement, chatbots represent just one way we can leverage this technology. Experimentation, iteration, and adaptability are key to refining these systems. With off-the-shelf solutions and increasingly powerful models, we now have more tools than ever to enhance and scale our work. Ultimately, while chatbots are one of the most intuitive and visible applications of LLMs, their potential goes far beyond conversation. These technologies open doors to new processes and innovations, empowering us to build even greater things.
Thank you to Ashley Hebler, Darla Cameron, Ryan, Alejandro Martínez-Cabrera and Jaden Edison for helping me throughout the process. And thank you to all the users who were willing to test and provided feedback!
Any questions, suggestions, or feedback: Please use this feedback form or email me at suraj.thapa@texastribune.org