The Texas Tribune Helpbot
Problem Statement
We use Slack at The Texas Tribune and like many other orgs out there we use a dedicated "help" channel for staff to get assistance on any IT problems, account access needs, office supply requests etc. This channel receives a high volume of questions, requiring team leads and senior management to monitor it closely to ensure timely responses. Below are some examples of the questions frequently asked.
- “Who can help me reset my password in Pass>”
- “Who can get our fellow set up on the system where her mobile phone shows our organization’s name when she makes outgoing calls for community outreach? (I’ve forgotten the name of the system!)”
- “Who can add my teammate to the email @example distribution lists?”
Proposed Solution
To address questions like these, we created an FAQ document in a Q&A format. Our engineering manager also converted some tables into the Q&A format. The answers to the questions are as follows:
-
“Who can help me reset my password in Pass?>”
- G and A are administrators of the 1Password vault and can help you reset your password or regain access to 1Password.
-
“Who can get our fellow set up on the system where her mobile phone shows our organization’s name when she makes outgoing calls for community outreach? (I’ve forgotten the name of the system!)”
- ITeam can help set up your fellow's phone so that it shows “Organization Name” for outgoing community outreach calls.
-
“Who can add my teammate to the email @example distribution lists?”
- A and B can add your teammate to the email distribution lists.
The proposed solution was to use AI technology to guide people to the right resources. So, we started building a Retrieval-Augmented Generation (RAG) bot, integrated with Slack, to help direct people to the right people and places efficiently.
Implementation
Attempt 1
We tested Google Cloud's Agent Builder, and while it was easy to set up and integrate with Slack, the app didn’t offer much control over settings and we found it was inconsistent at times. These issues with Agent Builder prevented us from going any further with their product.
Attempt 2
We turned to AWS for a more custom solution and found exactly what we needed with AWS Bedrock. It provided greater control over how we work with different models and parameters, offering the flexibility we were looking for.
How does this work?
We leverage AWS Bedrock to interact with LLM models and integrate Slack via AWS Lambda. Let’s walk through the figure below to understand the process. A user asks a question in Slack, and the Lambda function sends it to Amazon Bedrock, which processes the query and returns the response to Slack. For more details on this integration, check out the AWS Machine Learning blog (the image below is sourced from that blog).
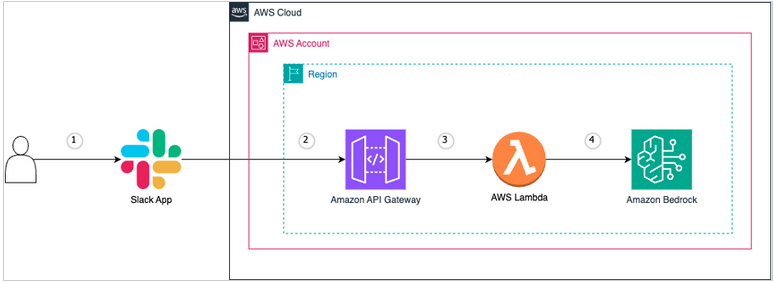
To implement a RAG system based solely on our documents, I converted the google documents to pdf, stored the PDF files to S3, and used AWS Bedrock’s knowledge base feature for vector data (embeddings). The knowledge base is a managed solution designed to store vector representations of documents, making retrieval fast and efficient.
Models for embedding and text generations
For the embeddings, we used Amazon’s Titan Embeddings G1 - Textv1.2, and opted for a semantic chunking strategy when processing the documents. During initial testing, I found that semantic chunking produced the best results for our use case. Next, I chose Amazon Bedrock's AI agent feature because we wanted a tool similar to Google’s Agent Builder. You can learn more about Agents and their capabilities here. One of the key advantages of using Agent is that other team members can easily modify agents directly in the AWS console. Whether it's updating the model, knowledge base, prompts, or parameters, the team has the flexibility to make changes without relying on extensive code updates. Finally, for model selection, I went with Claude 3 Sonnet, which performed exceptionally well for our use case.
To minimize the maintenance, we decided early on to build the serverless infrastructure. I used AWS SAM, which allows us to keep most of the stack in our codebase. This setup includes AWS CloudFormation, Lambda, Secrets Manager, and CloudWatch.
Bonus: The Texas Tribune Festival
Just before The Texas Tribune Festival 2024, we uploaded the info desk document into S3 and integrated it into the helpbot’s knowledge base. The helpbot could answer Festival-related questions. However, we noticed that responses to questions involving tables were less accurate, highlighting the importance of structuring documents in a clear question-and-answer format. As a potential improvement, we could consider using the Claude model to generate embeddings instead of the Titan model—a great idea for a future blog post! 🤔
Results
The helpbot has been incredibly useful so far. Users can ask questions either in the all-help public channel or through direct messages with the bot. What makes this bot, particularly the Claude model, stand out is its strong understanding of human intent. You can phrase questions naturally, even with minor errors, and it will still provide accurate answers—assuming the information is covered in the Q&A document.
Lessons Learned
There are many valuable lessons we've learned from this experience, outlined below:
-
Expanding Question Coverage: Sometimes the helpbot can’t answer new questions that arise. This gap can erode user trust if their queries aren’t answered right away. To avoid this, it's essential to build a comprehensive Q&A set from the start and continuously update it.
-
Early Evaluation Planning: It’s important to think about how you’ll evaluate the bot early on. While the bot may perform well for certain queries, creating both manual and automated evaluation processes is key. Develop your test criteria and dataset upfront, and continually test the bot against any changes. (This could be a blog post in itself! 😉)
-
Performance Measurement: Tracking performance is crucial. We’ve been using CloudWatch dashboards to gather metrics, but moving forward, we should be more structured in how we measure success.
-
Managing Scope: Once users start interacting with the bot, they may ask questions outside its intended scope. Some of these can be incorporated, while others may not be relevant. It’s important to manage these expectations.
-
Prompt Customization: As obvious as it sounds, we had to fine-tune the bot’s prompts to better suit our needs and improve its accuracy.
-
Keeping Information Up-to-Date: Personnel changes are inevitable, and since the bot is often to direct users to the right departments or individuals, we must keep its information current as people leave or roles change.
-
Content-Rich Knowledge Base: Continuously update the bot with as many questions as possible. A rich, evolving knowledge base ensures that it remains useful and relevant.
Improvements
-
We plan to implement conversation threading within message threads, which is more of a software development challenge than an AI engineering one. We're excited to tackle this feature in the future.
-
Another improvement is the ability to handle both tables and Q&A formats within a single document seamlessly—this might even be worth another blog post! 😉
Conclusion
The helpbot is a very simple, yet powerful, tool we have built. This was great because it saved time for people who had to constantly check the slack channel. It gave us a great space to test out these tools and learn from it. Some of the lessons learned regarding evaluation, metrics, and data type will help us greatly in the future iterations.
Thank you to Ashley Hebler and Darla Cameron for bringing these ideas and helping me throughout the process. It’s been a real treat to bring this to life and learn together from it. And thank you to all the users who patiently waited for this tool to get better and provided consistent feedback!